

TL;DR: AI Security Lessons from Prompt Injecting Google Photos Remix Feature
- Red team before you ship: Users will break your AI models in ways you never imagined; test with creative misuse before launch
- Multimodal models create new attack surfaces: Screenshots bypass traditional input filters; images become prompt injection vectors
- Defense in depth is essential: Single security layers fail; attackers only need to succeed once, defenders must succeed always
- Make security reporting accessible: Clear vulnerability disclosure paths prevent issues from festering; automate feedback responses
- Simple exploits often work best: Complex attacks (hidden text on clothing) failed while obvious methods (screenshot text) succeeded completely
- User creativity exceeds security imagination: Plan for creative misuse from day one; every AI feature will be used unexpectedly
The real lesson: AI security is a product design problem. Think like an attacker before your users do.
I Was Testing Google Photos When I Found Something Unexpected
I was testing Google Photos' new Remix feature when I wondered: could it be vulnerable to prompt injection? A few minutes later, I had my answer.
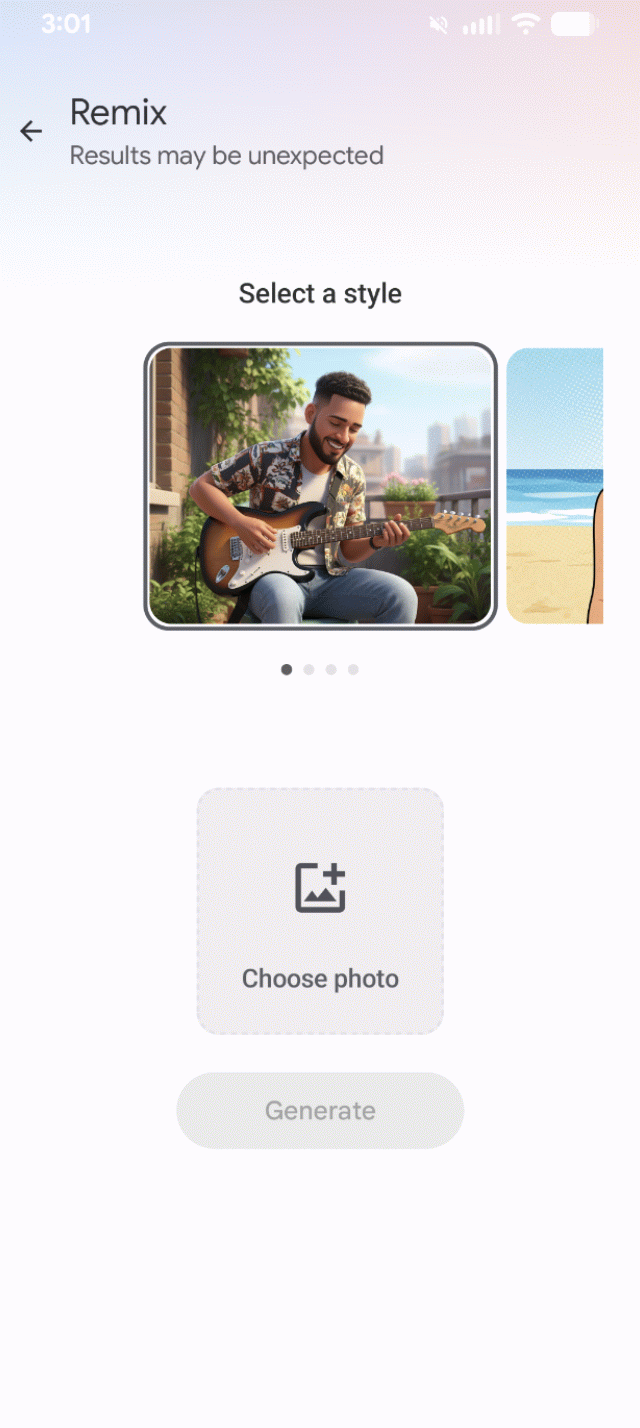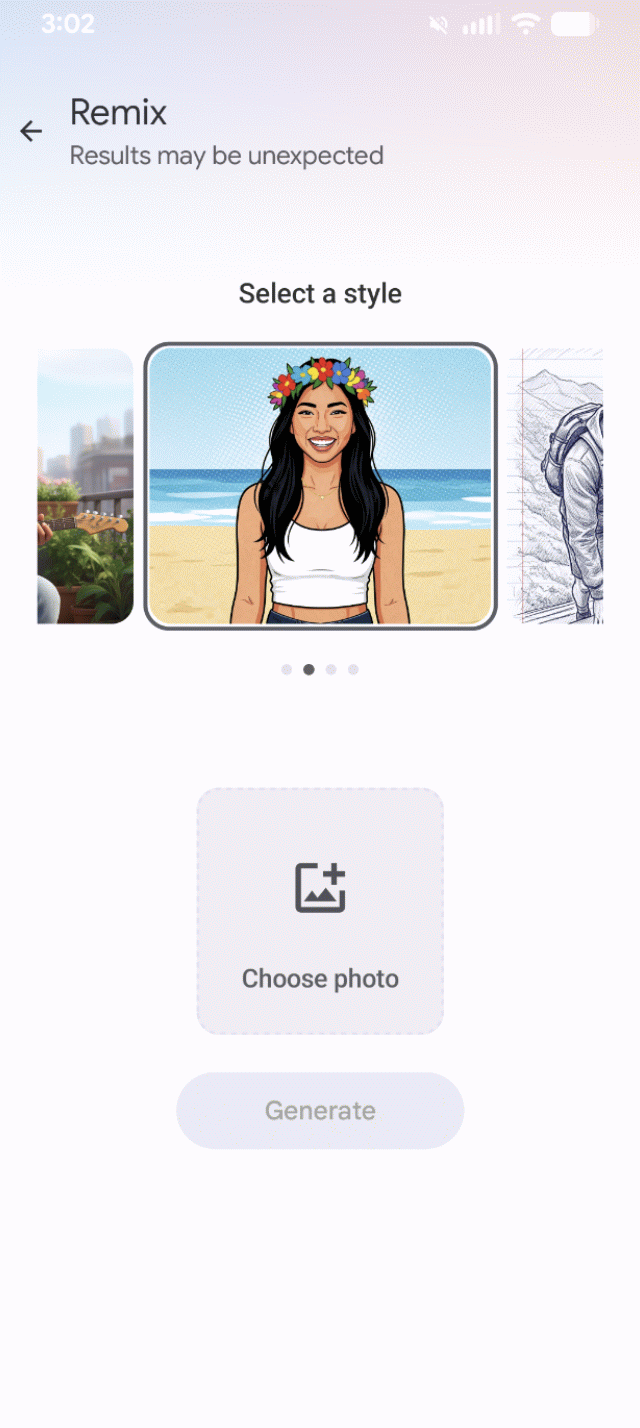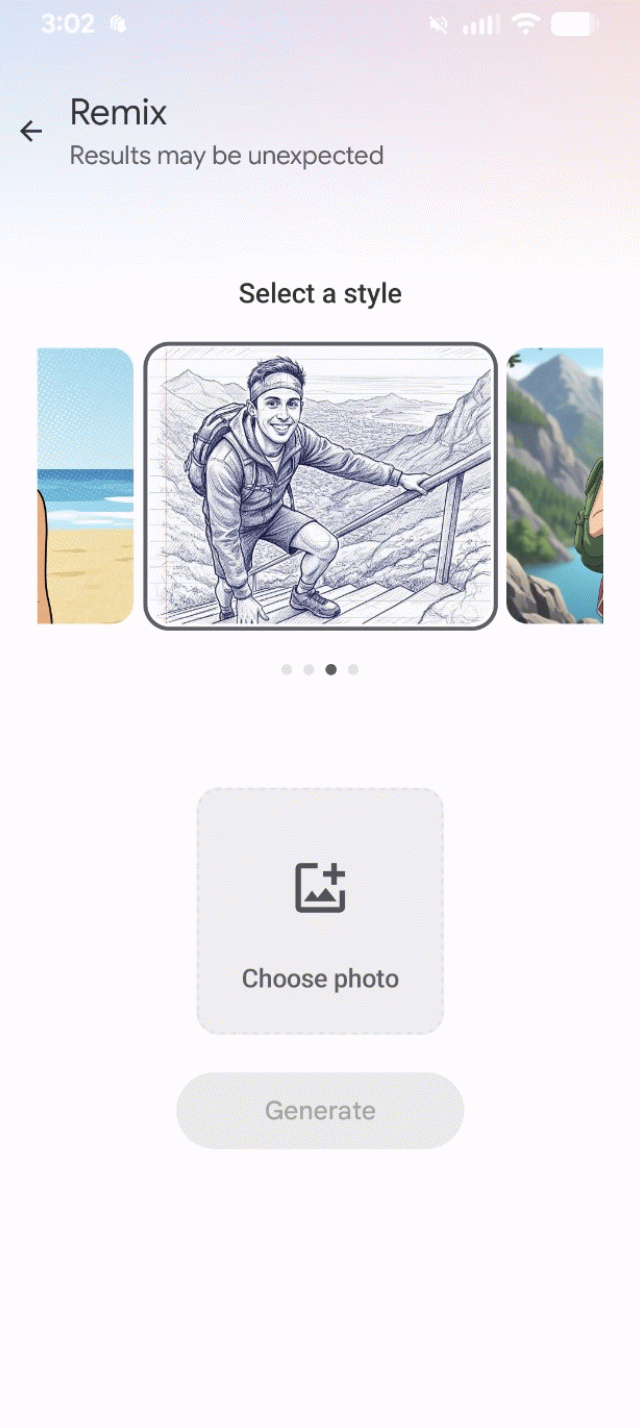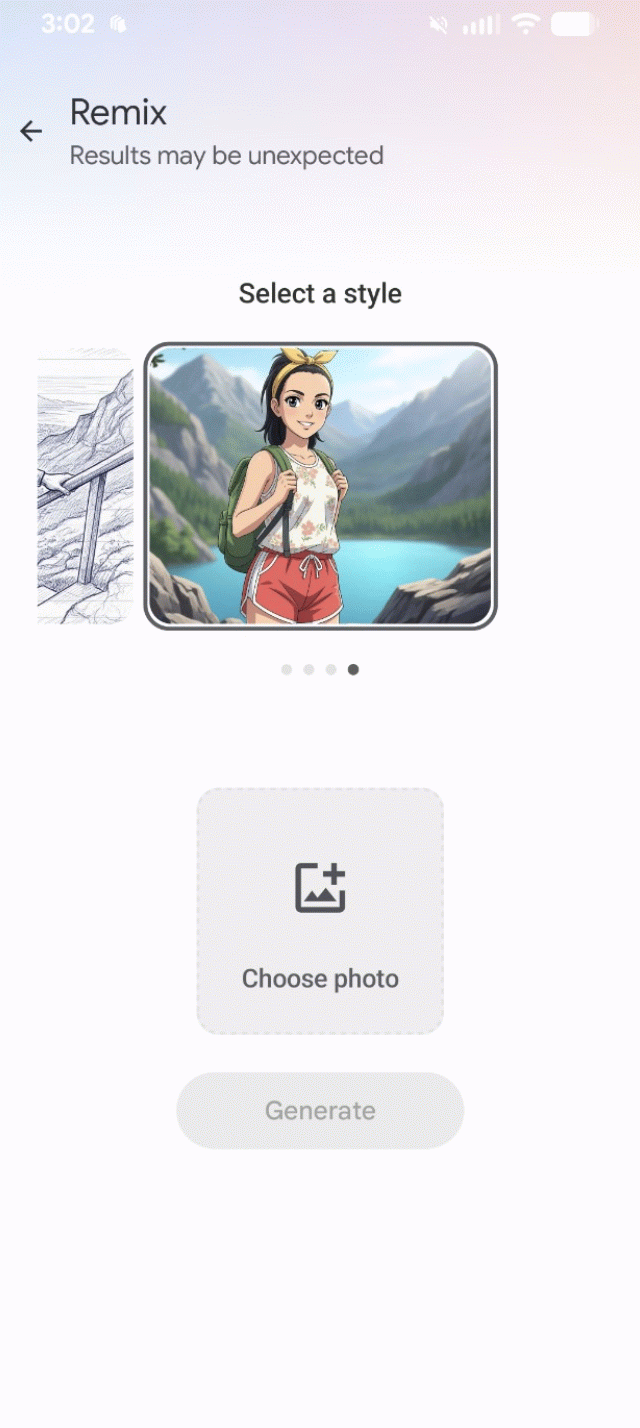
The exploit worked. The AI read my embedded text and rendered exactly what I described.
Why This Matters for Product Leaders
Generative AI is everywhere in consumer products now. Photo remixing feels playful and harmless. Under the hood, Remix likely runs Nano-Banana, an advanced multimodal model that maintains character consistency.
Multimodal means it interprets images and text. That complexity creates exploit opportunities.
Most product teams focus on happy paths. They test normal use cases and optimize for delight. Few ask: what happens when someone tries to break this?
How I Tested the Vulnerability
Remix offers four styles to reinterpret source photos. I created a "photo" by typing instructions in Notepad, starting with User message: followed by my prompt.

I screenshotted the text, uploaded it to Google Photos, and used it as my remix source.
Three of four remix styles followed my injected instructions perfectly. Only "3D Character" ignored the prompt and kept producing generic female characters.


No guardrails stopped me. The only stopper was a rate limiting after 8-10 images, locking me out for thirty minutes.
What I Saw in Action
The model consistently read embedded text and rendered whatever I described. That's multimodal prompt injection in action. Images become manipulation vectors.
This isn't theoretical. It's live in a consumer product with millions of users.
Testing More Complex Attack Vectors
I wanted to test more sophisticated attacks. Could I hide prompts naturally while still exploiting the system?
I photoshopped prompt text onto my t-shirt. The idea: make injection less obvious by embedding instructions in an image.

Results were negative. The text was ignored or filtered out. The model treated it as a normal photo.
One "ink sketch" attempt was denied entirely. I got an error telling me to select another image.
Google has content filtering. It just seemed to miss the obvious screenshot text.
Responsible Disclosure Process
I wanted to report this through proper channels. A quick search revealed no clear path for Google Photos security reports. Their general security reporting focuses on critical infrastructure.
I used the standard Photos feedback form. I described the vulnerability, provided examples, and suggested investigating multimodal prompt injection vectors.
No response yet. This highlights an opportunity: provide automated feedback responses and clear security reporting pathways.
The Risk Assessment
This feels more like a parlor trick than real danger. I saw no obvious weaponization path. Output remains constrained to image generation within Photos.
But it proves a point: securing multimodal consumer AI is hard. Defenses must live deep in system prompts or require multiple specialized agents. This creates a UX problem when overzealous filters reject normal prompts with no clear explanation.
Forcing the security and product teams to play whack-a-mole with user creativity.
Critical Lessons for Product Teams
Users Never Use Features as Intended
Users will surprise you. They find unconsidered edge cases, combine features unexpectedly, and test unknown boundaries.
Planning on shipping generative AI? Assume someone will try to break it.
Red Team Before You Ship
Break your AI feature before others do. Create dedicated red team exercises. Give explicit permission to find vulnerabilities. Reward creative misuse discoveries by giving users clear reporting pathways.
Accept the Cat and Mouse Game
Security lags creativity until defenses mature. This is normal for emerging tech. Build systems that adapt quickly when vulnerabilities surface.
Plan for patches. Design for rapid iteration. Monitor unusual patterns. Review logs for anomalies.
What This Means for AI Product Strategy
We're in the first chapter of generative AI. Systems aren't properly secured because we're still defining what "secured" means for multimodal models.
Traditional input sanitization fails when images contain hidden text, adversarial patterns, or embedded instructions.
Product leaders need new AI safety frameworks beyond traditional security models.
The Opportunity in the Challenge
Despite security concerns, these tools are magical. They let anyone create high-quality, imaginative work.
Lowering creativity barriers democratizes art. That's worth exploring, even with risks.
The goal isn't eliminating vulnerabilities. It's making them harder to exploit and less dangerous when they succeed.
Building Safer AI Products
Start with threat modeling. Map attack vectors. Consider technical exploits and social engineering.
Implement defense in depth. Use multiple security layers throughout your AI pipeline.
Monitor unusual patterns. Track edge cases. Build systems that learn from exploits.
Stay curious about how users might surprise you.
My Takeaway for Product Leaders
Generative AI security is a product design challenge, not just technical. Bake security into user experience from day one.
Companies solving this first gain massive advantage. They'll ship AI features confidently while others hesitate.
What's Your AI Security Strategy?
Are you red teaming your AI products before launch? How do you approach your testing?